Researchers at Stanford develop ChatGPT-like bot for academic research
Scientists say their chatbot Alpaca is only for academic research and not for general use, in the near future

Researchers of artificial intelligence (AI) from Stanford University developed their ChatGPT-like chatbot demo Alpaca in less than two months but terminated it citing “hosting costs and the inadequacies of content filters” in the large language model’s (LLM) behaviour.
The termination announcement was made less than a week after it was released, as per Stanford Daily.
The source code of the ChatGPT model of Stanford — developed for less than $600 — is available publicly.
According to researchers, their chatbot model had a similar performance to OpenAI's ChatGPT 3.5.
Scientists in their announcement said that their chatbot Alpaca is only for academic research and not for general use, in the near future.
Alpaca researcher Tatsunori Hashimoto of the Computer Science Department said: "We think the interesting work is in developing methods on top of Alpaca [since the dataset itself is just a combination of known ideas], so we don’t have current plans along the lines of making more datasets of the same kind or scaling up the model,"
Alpaca was developed on Meta AI's LLaMA 7B model and generated training data with the method known as self-instruct.
Adjunct professor Douwe Kiela noted that “As soon as the LLaMA model came out, the race was on.”
Kiela who also worked as an AI researcher at Facebook said that "Somebody was going to be the first to instruction-finetune the model, and so the Alpaca team was the first … and that’s one of the reasons it kind of went viral."
"It's a really, really cool, simple idea, and they executed really well."
Hashimoto said that the "LLaMA base model is trained to predict the next word on internet data and that instruction-finetuning modifies the model to prefer completions that follow instructions over those that do not."
The source code of Alpaca is available on GitHub — a source code sharing platform — and was viewed 17,500 times. More than 2,400 people have used the code for their own model.
"I think much of the observed performance of Alpaca comes from LLaMA, and so the base language model is still a key bottleneck," Hashimoto stated.
As the use of artificial intelligence systems has been increasing with every passing day, scientists and experts have been debating over the publishing of the source code, data used by companies and their methods to train their AI models and the overall transparency of the technology.
He was of the view that "I think one of the safest ways to move forward with this technology is to make sure that it is not in too few hands."
"We need to have places like Stanford, doing cutting-edge research on these large language models in the open. So I thought it was very encouraging that Stanford is still actually one of the big players in this large language model space," Kiela noted.



-
 Shanghai Fusion ‘Artificial Sun’ achieves groundbreaking results with plasma control record
Shanghai Fusion ‘Artificial Sun’ achieves groundbreaking results with plasma control record -
 Polar vortex ‘exceptional’ disruption: Rare shift signals extreme February winter
Polar vortex ‘exceptional’ disruption: Rare shift signals extreme February winter -
 Netherlands repatriates 3500-year-old Egyptian sculpture looted during Arab Spring
Netherlands repatriates 3500-year-old Egyptian sculpture looted during Arab Spring -
 Archaeologists recreate 3,500-year-old Egyptian perfumes for modern museums
Archaeologists recreate 3,500-year-old Egyptian perfumes for modern museums -
 Smartphones in orbit? NASA’s Crew-12 and Artemis II missions to use latest mobile tech
Smartphones in orbit? NASA’s Crew-12 and Artemis II missions to use latest mobile tech -
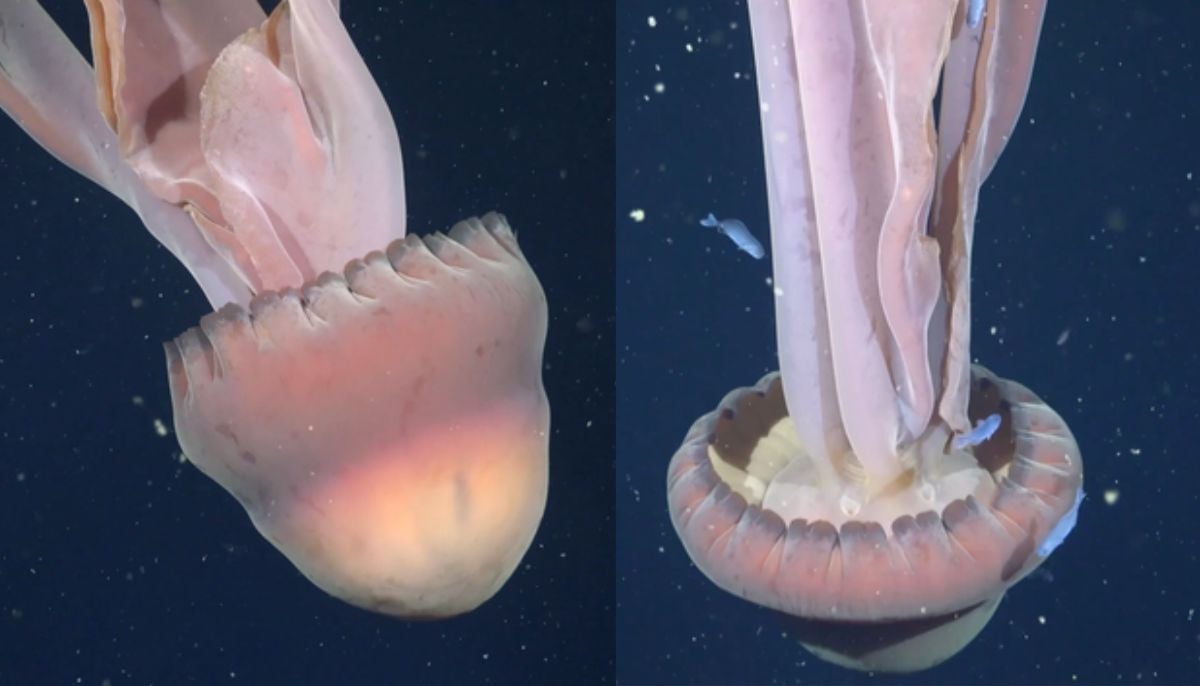 Rare deep-sea discovery: ‘School bus-size’ phantom jellyfish spotted in Argentina
Rare deep-sea discovery: ‘School bus-size’ phantom jellyfish spotted in Argentina -
 NASA eyes March moon mission launch following test run setbacks
NASA eyes March moon mission launch following test run setbacks -
 February offers 8 must-see sky events including rare eclipse and planet parade
February offers 8 must-see sky events including rare eclipse and planet parade